
빼빼로데이에도 코테 스터디는 계속됩니다. 오늘은 15일 차! 힘차게 문제 풀어봅시다.
문제 설명
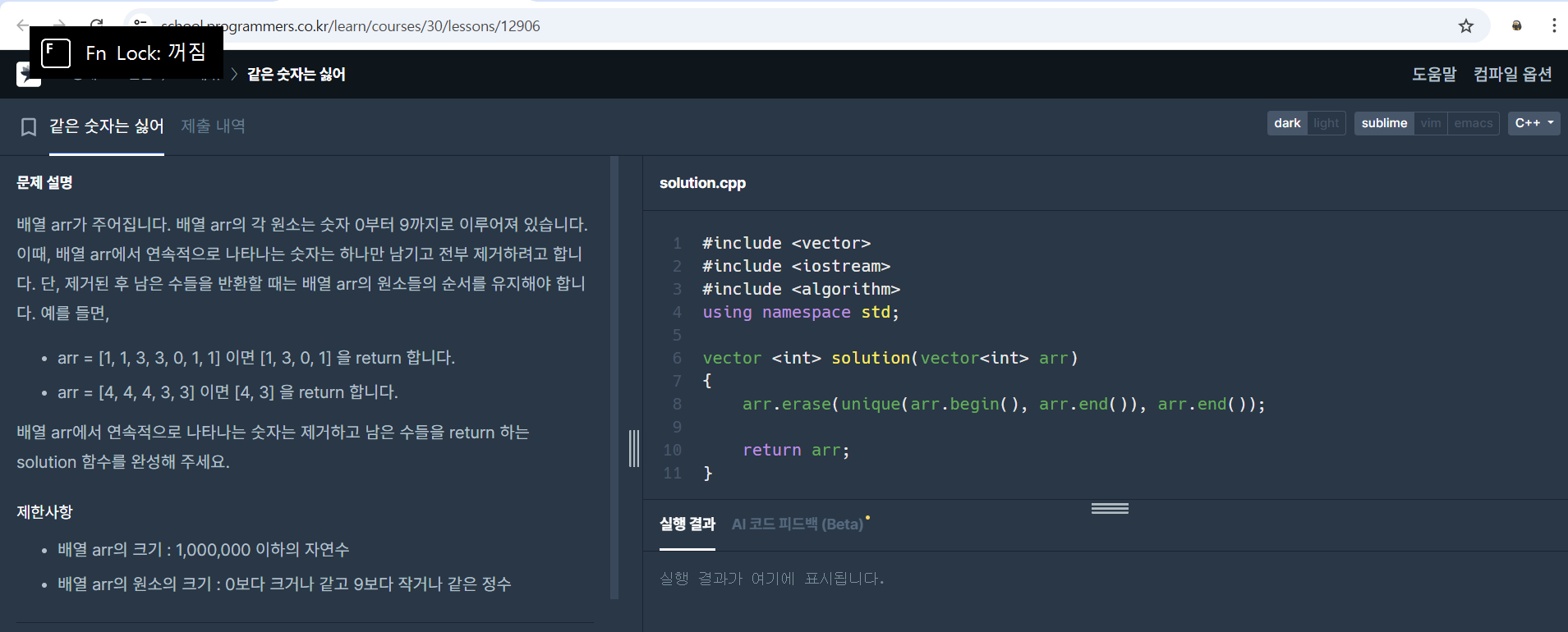
배열이 주어지면 배열 속 정수의 중복을 제거하여 다시 배열로 출력하는 문제입니다.
단순히 말해서 중복된 요소를 제거하는 문제입니다.
생각 흐름
단순한 벡터 구현 문제라는 것을 단번에 알아차렸던 것 같습니다.
배열로 들어오는 숫자 배열 속 중복된 숫자를 삭제해버리면 되는 문제였기 때문에 이와 관련된 함수를 생각해 봤던 것 같습니다.
일일이 반복문으로 비교하면서 다른 배열에 넣어줘도 되겠지만 C++ STL에는 unique라는 함수가 있었다는 것을 기억해 냈기 때문에 쉽게 풀었던 것 같습니다.
#include <vector>
#include <iostream>
#include <algorithm>
using namespace std;
vector <int> solution(vector<int> arr)
{
arr.erase(unique(arr.begin(), arr.end()), arr.end());
return arr;
}
공부한 내용 정리
오늘은 역대급으로 쉽고 빠르게 푼 것 같아서 다시 한번 아는 개념 정리하는 것으로 대체하려고 합니다.
1. unique() 함수
- vector 배열에서 중복되지 않는 원소들을 앞에서부터 채워나가는 함수이다
- <algorithm> 헤더 파일에 존재한다.
- 중복되지 않는 원소들을 앞에서부터 채워나가는 역할을 하기 때문에 남은 뒷부분은 그대로 vector의 원소값이 존재한다.
--> 따라서, 중복된 원소들을 제거해주려면 erase() 함수와 같이 써야 하는데..
- erase () 함수는 vector 배열에서 특정 원소를 삭제하는 함수이다.
- v.erase(시작 지점, 끝 지점) 같이 쓸 수 있으며, 시작지점부터 끝 지점까지의 원소를 지울 수 있다.
이를 이용하면 v.erase(unique(v.begin(), v.end()), v.end()); 와 같이 사용하며 중복된 원소를 삭제할 수 있다.
unique 함수에 관해 더 찾다가, 함수의 작동방식에 대해 자세히 적어놓은 블로그를 보았다.
이 글쓴이는 unique 함수가 어떻게 작동하는지 제대로 알고 싶어서 공식문서를 참조해 공부를 해보았다고 한다
공식문서에서는 unique 함수를 "Remove consecutive duplicates in range"라고 설명하고 있다고 한다.
대충 해석해 보면 범위 내에서 연속적으로 존재하는 요소들을 삭제해 준다"라는 뜻이다.
consecutive가 중요한데,
예로, 10 10 20 30 20 10 10이라는 배열을 10 20 30 20 10 10 10으로 바꾸어 준다는 뜻이다.
또한 이 함수에서 중요한 부분은 정렬 후에 배열의 사이즈를 바꾸어주지 않는 것이다.
일단, 어느 정도 함수에 대한 정의는 알게 된 것 같으니 작동 방식에 대해 알아보자.
작동 방식
unique 함수는 parameter로 range를 받는다. iterator 형식으로 범위의 시작인 first와 범위의 끝인 last 2개를 받는다. 이때 last는 마지막 요소 그다음을 의미한다. (그래서 마지막 요소 다음을 가리키는 end 함수를 자주 사용한다.)
그렇게 first와 last iterator를 받고 나서 unique가 작동되는데 작동원리는 아래와 같다.
template <class ForwardIterator>
ForwardIterator unique (ForwardIterator first, ForwardIterator last)
{
if (first==last) return last;
ForwardIterator result = first;
while (++first != last)
{
if (!(*result == *first)) // or: if (!pred(*result,*first)) for version (2)
*(++result)=*first;
}
return ++result;
}
이 글쓴이는 그림까지 그려서 설명을 해주고 있다.
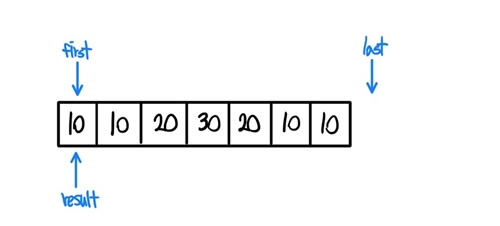
- 가장 기초상태이다. result라는 iterator까지 만들어서 first와 같은 주소를 가리키고 있는 형태이다.
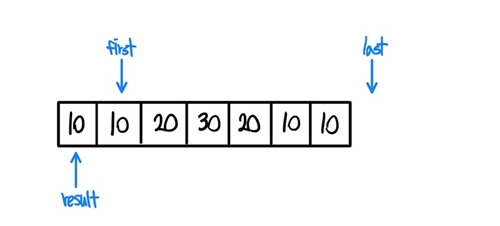
- 이후에 while (++first!= last)를 실행하면서 first를 옮긴다.
- 이후 if (!(*result == *first)) 구문을 실행한다. 이 구문은 result가 가리키는 값과 first가 가리키는 값이 다르면 참을 반환한다. 현재는 값이 10으로 같기 때문에 false를 반환하고 다시 while문으로 이동한다.
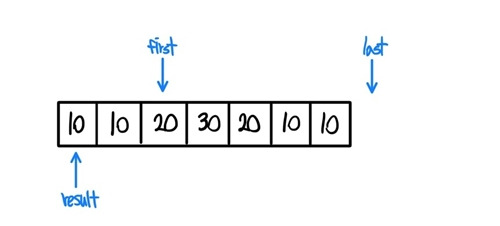
- 1번과 같은 과정으로 first를 옮기고 last와 다른지 검사한다.

- 이번에는 first와 result가 가리키는 값이 다르기에 if (!(*result == *first)) 구문이 참을 반환한다. 이후에 *(++result)=*first; 구문을 실행한다. 우선 ++result를 실행하고,
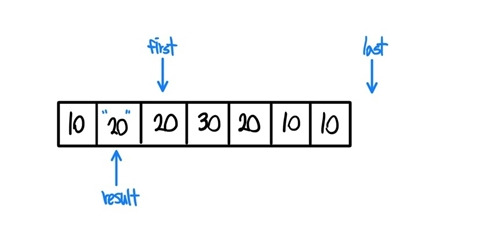
- 곧바로 result값을 first값으로 갱신해 준다. 이러한 과정의 반복이다.
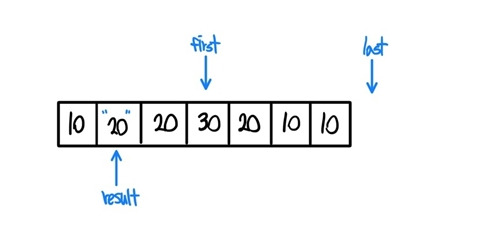
- 조금 더 살펴보자, first는 이동하고 result와 다른지 검사한다.
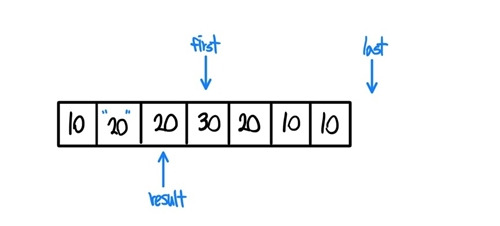
- 값이 20과 30으로 다르기에 if문은 참을 반환하고, result가 한 칸 옮겨간다.
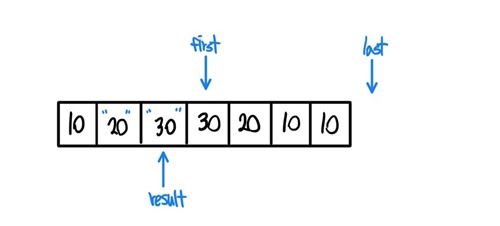
- 이후에 result가 가리키는 곳의 값을 first가 가리키는 값으로 갱신한다.
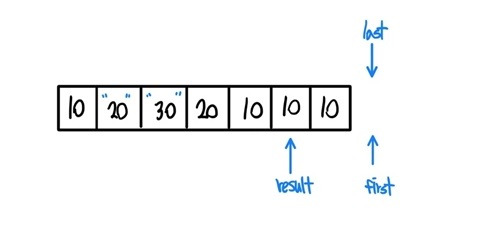
이 블로그를 보면서 STL 속 unique()에 대한 이해는 제대로 하였다.
제대로 작동방식까지 그림으로 보고 공부하니 이해가 쉬웠다. 앞으로 잘 활용하면 될 것 같다.
'코테 > 항해99' 카테고리의 다른 글
| [99클럽 코테 스터디 19일차 TIL] #힙 1 (4) | 2024.11.15 |
|---|---|
| [99클럽 코테 스터디 16일차 TIL] #스택/ 큐 5 (1) | 2024.11.12 |
| [99클럽 코테 스터디 14일차 TIL] #스택/ 큐 3 (3) | 2024.11.11 |
| [99클럽 코테 스터디 13일차 TIL] #스택/큐 2 (0) | 2024.11.10 |
| [99클럽 코테 스터디 12일차 TIL] #스택/ 큐 1 (0) | 2024.11.09 |