
스벅 카페에 앉아서 블로그를 써보네요. 오늘은 20일 차입니다. 열심히 풀어보겠습니다.
문제 설명
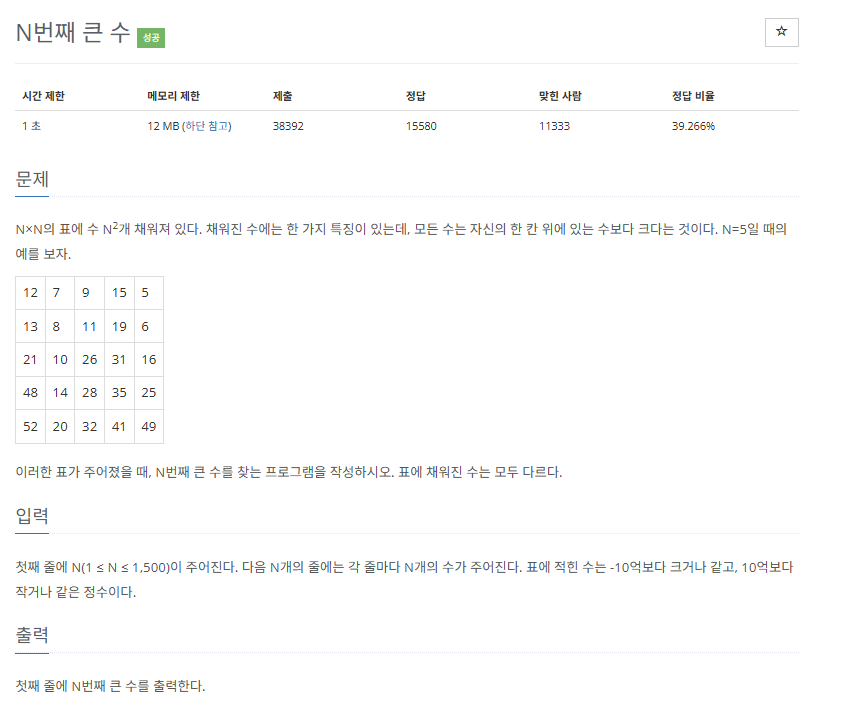
정수 N이 주어지고 N*N의 숫자표가 주어집니다. 이러한 숫자표 중에서 N번째로 큰 수를 출력하는 간단해 보이는 문제입니다.
https://www.acmicpc.net/problem/2075
생각 흐름
처음 이 문제를 봤을 때는, 문제 길이가 그렇게 길지가 않아서 쉬운 문제구나 싶었습니다.
정수 n이랑 n*n으로 된 숫자표가 주어지고 이것들 중에서 n번째로 큰 수를 찾는 문제였어요.
어제 우선순위 큐와 min heap에 대한 문제를 풀었어서 우선순위큐로 쉽게 해결할 수 있겠구나 싶어서 반복문을 돌려서
자신 있게 풀어냈는데 한 가지를 간과한 게 있었습니다.
바로 메모리와 시간 제한이였죠. n*n번 반복문을 돌리면 시간, 메모리초과가 난다는 사실을 몰랐던 거예요.
저는 다시 코드를 짜보기로 했죠.
천천히 생각해 보면서 n*n개의 수가 들어가지만 n번째 큰 수를 출력하니 나머지 n*n-n의 수는 그냥 단순히 저장만 돼있다는 생각을 하였습니다. 어우 메모리 아깝죠
음,,, 이것을 어떻게 해결할까 고민하다가 pq.size()를 n으로 고정하고 크기순으로 저장한다면 상위 5개의 수 말고는 제거할 수 있겠다는 생각을 하였습니다.
그렇기 되려면 한번 생각을 새롭게 해야 하는데 내림차순으로 우선순위큐를 사용할 게 아니라 오름차순, 즉 작은 수가 top()의 위치에 있게 만들어야 하는 것이었습니다.
priority_queue <int, vector <int>, greater <int>> pq; 로 오름차순으로 배열이 정리되게 우선순위큐를 선언한 후
여기에 pq.size() < n의 조건문을 걸어 n개의 수만 저장해 주었습니다.
그리고 마지막으론 pq.top()을 출력해 주어 마무리했습니다.
틀렸던 코드들
#include <iostream>
#include <queue>
using namespace std;
int main () {
int n;
cin >> n;
priority_queue <int> pq; // 수를 저장할 우선순위 큐 구현 pq
for (int i = 0; i < n*n; i++) {
int temp;
cin >> temp;
pq.push(temp);
}
for (int i = 0; i < n-1; i++) {
pq.pop();
}
cout << pq.top() << "\n";
}
메모리 초과
#include <iostream>
#include <queue>
using namespace std;
int main () {
int n;
cin >> n;
priority_queue <int, vector<int>, greater<int>> pq; // 오름차순으로 저장하는 우선순위 큐 pq
for (int i = 0; i < n; i++) { // n*n 번을 반복문을 돌려
for (int j = 0; j < n; j++) {
int temp;
cin >> temp; // 수를 받아옴
pq.push(temp); // 일단 저장하고
if (pq.size() > n) { // pq의 사이즈가 n을 넘어가면
pq.pop(); // pq의 top()을 제거해줌 (가장 작은 수)
}
}
}
cout << pq.top() << "\n"; // 결국 top엔 5번째 큰 수가 저장되게 됨
return 0;
}
시간 초과
#include <bits/stdc++.h>
using namespace std;
int main () {
ios_base::sync_with_stdio(NULL);
cin.tie(NULL); cout.tie(NULL);
int n;
cin >> n;
priority_queue <int, vector<int>, greater<int>> pq; // 오름차순으로 저장하는 우선순위 큐 pq
int temp;
for (int i = 0; i < n*n; i++) {
cin >> temp; // 수를 받아옴
pq.push(temp); // 일단 저장하고
if (pq.size() > n) { // pq의 사이즈가 n을 넘어가면
pq.pop(); // pq의 top()을 제거해줌 (가장 작은 수)
}
}
cout << pq.top() << "\n"; // 결국 top엔 5번째 큰 수가 저장되게 됨
return 0;
}
드디어 성공
공부한 내용 정리
우선, 오늘 크게 깨달은 것은 문제를 빨리 푸는 것도 중요하지만 문제를 제대로 이해하는 것이 중요하다는 것을 또다시 배웠습니다.
무려 7번을 코드 재작성을 했기 때문이죠.
점점 문제가 어려워지는 것도 있는데 이러한 문제 속 세세한 조건들도 꼭 봐야 한다는 것을 깨달았습니다.
문제를 풀고 생각해 보니 문제의 조건 중 같은 열 속의 숫자가 행이 커질수록 커진다는 조건을 왜 추가했을까 고민해 보았습니다. 아마 우선순위큐를 떠올려라, 아님 크기순으로 저장하는 배열을 만들라는 암묵적인 힌트를 준 게 아닐까라는 생각을 하였습니다.
오늘은 무엇을 공부해 볼 까 고민하다가 제가 아직 이중배열과 pair 이놈을 쓰는 게 아직 미숙하다는 것을 알게 되었습니다.
항시 이중배열만 나오면 머리가 하얘진다고 해야 하나...
아 이것을 공부하는 이유는 숫자표가 나와서 이것들로도 문제를 접근했었기 때문입니다.
아무튼 오늘은 이놈들을 제대로 때려 부수겠습니다.
1. pair 클래스
1) pair class
pair 클래스는 사용자가 지정한 2개의 타입의 데이터를 저장하는 데 사용합니다.
서로 연관된 2개의 데이터를 한 쌍으로 묶어서 다룰 때 사용하면 편리합니다.
2) pair header file
pair 클래스는 #include <utility>라는 헤더파일에 존재하는 STL입니다.
#include<utility> // pair의 헤더파일
그러나, vector 헤더파일을 사용해도 되는데, algorithm, vector 헤더파일에 이미 포함되어 있기 때문입니다.
#include<algorithm> // utility 헤더파일이 포함됨.
#include<vector> // utility 헤더파일이 포함됨.
3) pair 클래스의 형태
template <class T1, class T2> struct pair;
pair 클래스의 형태는 다음과 같고 t1, t2는 다음과 같이 접근합니다.
t1: first
t2: second
4) 함수의 사용법
pair <type1, type2> p
pair 클래스의 객체 p를 생성합니다. 객체 이름은 p가 아니어도 상관없습니다.
- p.first : p의 첫 번째 인자를 반환합니다.
- p.second : p의 두 번째 인자를 반환합니다.
- make_pair(값 1, 값2) : 값1, 값 2를 한 쌍으로 하는 pair를 만들어서 반환합니다.
p = make_pair(1, 2.1); //p.first = 1, p.second = 2.1과 동일
vector <pair <int, int>> p; // 이렇게도 가능
5) 객체의 대소 비교
pair 객체의 대소 비교를 할 수 있습니다.
pair 객체 간의 대소 비교를 진행하는 경우, 제일 먼저 첫 번째 값을 비교하고, 첫번째 값이 같으면 두 번째 값을 통해서 판단합니다.
#include<iostream>
#include<vector>
using namespace std;
void compare(pair<int, int> a, pair<int, int> b)
{
if (a > b)
cout << "첫 번째 인자가 더 큼." << endl;
else
cout << "두 번째 인자가 더 큼." << endl<<endl;
}
int main()
{
pair<int, int> a;
pair<int, int> b;
a = make_pair(2, 4);
b = make_pair(1, 5);
cout << "<a의 first가 b의 frist보다 큰 경우>" << endl;
compare(a, b); //first를 비교
a = make_pair(2, 7);
b = make_pair(2, 10);
cout << "<a의 first와 b의 frist가 같은 경우>" << endl;
compare(a, b); //second를 비교
return 0;
}
위의 내용들을 종합적으로 사용해 보겠습니다.
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
bool compare(pair<int, int> a, pair<int, int> b);
pair<int, int> p;
vector <pair< int, double >> q;
int main()
{
p.first = 1; //pair의 첫번째 인자에 접근
p.second = 10; //pair의 두번째 인자에 접근
cout << " p first value: " << p.first << endl;
cout << "p second value: " << p.second << endl<<endl;
p = make_pair(3, 4); //make_pair를 이용한 방법
cout << "*****make_pair을 이용한 방법*****" << endl;
cout << " p first value: " << p.first << endl;
cout << "p second value: " << p.second << endl<<endl;
cout << "**********vector와 pair를 함께 사용하는 방법*********" << endl;
q.push_back(make_pair(1, 1.2));
q.push_back(make_pair(3, 2.2));
q.push_back(make_pair(4, 3.2));
q.push_back(make_pair(2, 4.2));
for (int i = 0; i < q.size(); i++)
{
cout << "first: " << q[i].first << ", second: " << q[i].second << endl;
}
cout << endl;
sort(q.begin(), q.end(), compare); //sort를 이용해서 정렬
cout << "**********정렬 후*********" << endl;
for (int i = 0; i < q.size(); i++)
{
cout << "first: " << q[i].first << ", second: " << q[i].second << endl;
}
return 0;
}
bool compare(pair<int, int> a, pair<int, int> b)
{
return a.first < b.first;
}
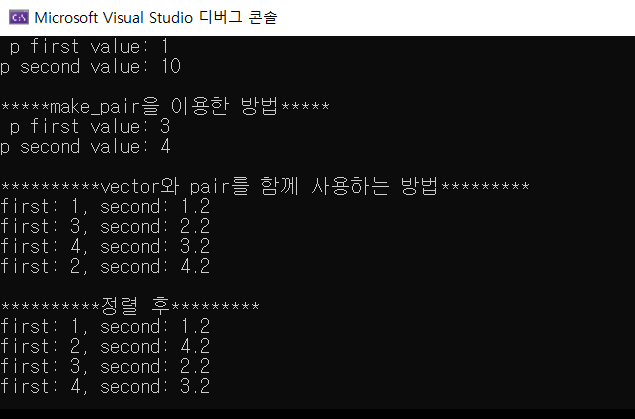
algorithm 헤더파일에 있는 sort 함수를 사용하면 pair.first을 기준으로 정렬이 됩니다.
'코테 > 항해99' 카테고리의 다른 글
| [99클럽 코테 스터디 23일차 TIL] #힙5 (1) | 2024.11.19 |
|---|---|
| [99클럽 코테 스터디 22일차 TIL] #힙4 (2) | 2024.11.18 |
| [99클럽 코테 스터디 19일차 TIL] #힙 1 (4) | 2024.11.15 |
| [99클럽 코테 스터디 16일차 TIL] #스택/ 큐 5 (1) | 2024.11.12 |
| [99클럽 코테 스터디 15일차 TIL] #스택/ 큐 4 (2) | 2024.11.11 |